
集群需求及依赖
K8S集群需求
根据官方文档需求部署相关集群,并创建对应权限的SA
- Kubernetes >= 1.9.
- KubeConfig, which has access to list, create, delete pods and services, configurable via ~/.kube/config.
- Enabled Kubernetes DNS.
- default service account with RBAC permissions to create, delete pods.
- Service account with permissions to create, edit, delete ConfigMaps.
Flink集群依赖
跟Spark类似,Flink依赖一些库/连接器,比如高可用的checkpoints需要hdfs进行存储,batch job写数据需要mysql连接器等. 相关连接器和jar包需要集成在镜像$FLINK_HOME/lib目录下
-
依赖HA架构的HDFS集群
-
Hadoop依赖,以下任选一个下载
- https://mvnrepository.com/artifact/org.apache.flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0
- https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
由于版本没办法灵活匹配,社区维护能力不足等原因,该jar包官方已经不在维护,详见Flink-11086
目前官方推荐方法是设置
export HADOOP_CLASSPATH=hadoop classpath环境变量,但这意味着你要集成整个hadoop目录 -
HDFS集群两个配置文件hdfs-site.xml和core-site.xml需要集成在镜像$HADOOP_CONF_DIR中
-
commons-cli-1.5.0.jar
-
-
依赖mysql作为报表数据输出
-
Native Kubernetes模式下,使用Application部署,只支持local模式,因此需要集成应用的jar包,并在提交任务时显示指定
local:///$FLINK_HOME/usrlib/Batch-Job.jar
K8S集群配置
-
创建SA并挂载镜像拉取secrets
kubectl -n flink create sa flink-sa kubectl -n flink patch serviceaccount flink-sa -p '{"imagePullSecrets": [{"name": "yourregistrykey"}]}' -
权限配置
kubef create rolebinding flink-role-binding --clusterrole=edit --serviceaccount=flink:flink-sa --namespace=flink -
更新DNS
默认挂载的configmap在kube-system:coredns下,需要更新为192.168.0.11自建DNS服务器以解析内部hostname
apiVersion: v1 data: Corefile: |2- .:53 { ... prometheus :9153 forward . 192.168.0.11 ... } kind: ConfigMap -
构建基础镜像
将上述的依赖和jar包统统打包在镜像里
FROM flink:1.15.2-java11 # 相关依赖jar包和连接器 ARG hadoop_jar=flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar ARG jdbc_jar=flink-connector-jdbc-1.15.2.jar ARG mysql_jar=mysql-connector-java-8.0.30.jar ARG common_cli=commons-cli-1.5.0.jar ARG hadoop_conf=core-site.xml ARG hdfs_conf=hdfs-site.xml ENV HADOOP_HOME=/hadoop RUN mkdir -p $HADOOP_HOME COPY --chown=flink:flink $hadoop_conf $HADOOP_HOME COPY --chown=flink:flink $hdfs_conf $HADOOP_HOME COPY --chown=flink:flink $hadoop_jar $FLINK_HOME/lib/ COPY --chown=flink:flink $common_cli $FLINK_HOME/lib/ COPY --chown=flink:flink $mysql_jar $FLINK_HOME/lib/ COPY --chown=flink:flink $jdbc_jar $FLINK_HOME/lib/ # 同步job的jar包 RUN mkdir -p $FLINK_HOME/usrlib COPY target/Streaming-Job.jar $FLINK_HOME/usrlib/Streaming-Job.jar COPY target/Batch-Job.jar $FLINK_HOME/usrlib/Batch-Job.jar USER flink
任务管理
任务提交
参数要点
- 资源分配
- prometheus监控
- hdfs
- 高可用HA
export HADOOP_CONF_DIR=/hadoop
./bin/flink run-application \
--detached \
--parallelism ${parallelism} \
--target kubernetes-application \
-Dkubernetes.cluster-id=$task_type \
-Dkubernetes.container.image=flink-java11:${release_num} \
-Dkubernetes.jobmanager.cpu=$jm_cpu \
-Dkubernetes.taskmanager.cpu=$tm_cpu \
-Dtaskmanager.numberOfTaskSlots=$tm_slot \
-Dtaskmanager.memory.process.size=${tm_mem}mb \
-Dtaskmanager.memory.managed.fraction=0.05 \
-Dtaskmanager.memory.network.fraction=0.05 \
-Dtaskmanager.memory.jvm-overhead.fraction=0.05 \
-Djobmanager.memory.process.size=700mb \
-Djobmanager.memory.enable-jvm-direct-memory-limit \
-Dfs.default-scheme=hdfs://datacluster \
-Dmetrics.reporter.promgateway.class=org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter \
-Dmetrics.reporter.promgateway.hostUrl=http://192.168.0.1:9091 \
-Dmetrics.reporter.promgateway.jobName=flink \
-Dmetrics.reporter.promgateway.deleteOnShutdown=true \
-Dmetrics.reporter.promgateway.randomJobNameSuffix=true \
-Dmetrics.reporter.promgateway.interval=60 \
-Dkubernetes.jobmanager.node-selector=task_type:streaming \
-Dkubernetes.taskmanager.node-selector=task_type:streaming \
-Dkubernetes.rest-service.exposed.type=NodePort \
-Dkubernetes.rest-service.exposed.node-port-address-type=ExternalIP \
-Dhigh-availability=org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory \
-Dhigh-availability.storageDir=hdfs://datacluster/flink/recovery \
-Drestart-strategy=fixed-delay \
-Drestart-strategy.fixed-delay.attempts=10 \
-Dkubernetes.namespace=flink \
-Dkubernetes.service-account=flink-sa \
-Denv.hadoop.conf.dir=/hadoop \
-Dkubernetes.container.image.pull-policy=Always \
-Dflink.hadoop.dfs.client.failover.proxy.provider.datacluster=org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider \
local:///opt/flink/usrlib/${tm_jar}
为了方便提交,已经集成在脚本submit_streaming_job.sh里
任务取消
HA方案下job_id固定为00000000000000000000000000000000
./bin/flink cancel --target kubernetes-application \
-Dkubernetes.namespace=flink \
-Dkubernetes.service-account=flink-sa \
-Dkubernetes.cluster-id=$cluster_id $job_id
任务列表
./bin/flink list --target kubernetes-application \
-Dkubernetes.namespace=flink \
-Dkubernetes.service-account=flink-sa \
-Dkubernetes.cluster-id=$cluster_id
常见问题
-
通过更新镜像的方式进行代码更新是不可行的,jobmanager实际是独立的pod,相关配置在configmap中,因此更新deployment的镜像文件并不会更新jobmanager的pod.详见讨论.正确的做法是先cacel job,再重新submit
bash cacel_streaming_job.sh task1 && bash submit_streaming_job.sh task1 $RELEASE_NUM -
外部prometheus监控需要配置自动发现pod,目前通过apiserver proxy的方式测试没成功,所以采用pushgateway的方式,缺点是必须手动清理过期数据.当前版本测试下来关于backpressured的相关指标并不准确
-Dmetrics.reporter.promgateway.hostUrl=http://192.168.0.1:9091 \ -Dmetrics.reporter.promgateway.jobName=flink \ -Dmetrics.reporter.promgateway.deleteOnShutdown=true \ -Dmetrics.reporter.promgateway.randomJobNameSuffix=true \ -Dmetrics.reporter.promgateway.interval=60 \ -
内存配置,据官方文档阐述,只需要配置
jobmanager.memory.process.size和taskmanager.memory.process.size即可,其他的内存会自动计算,但实际应用下来,一些默认系数会偏大,导致出现跟最大值最小值不匹配的报错.因此,自主定义更为可靠. 为了更加方便计算,我整理了一个表格公式- 一些带有默认值的
- JVM Metaspace = 256
- JVM Heap/Framework Heap = 128
- Direct Memory/Framework Off-Heap=128
- 一些带有默认系数的
- JVM Overhead= Max(Total Process Memory * fraction JVM Overhead, 192) min-max: (192,1000)
- Off-Heap Memory/Managed Memory = (Total Process Memory - Mem JVM metaspace - Mem JVM Overhead) * fraction Managed Memory
- Direct Memory/Network = ((Total Process Memory - Mem JVM metaspace - Mem JVM Overhead) * fraction network)
- 自动计算的
- JVM Heap/Task Heap = Total Process Memory - JVM Metaspace Memory - JVM Overhead Memory - Framework Heap − Framwork Off-Heap - Task Off-Heap - Managed Memory - Network
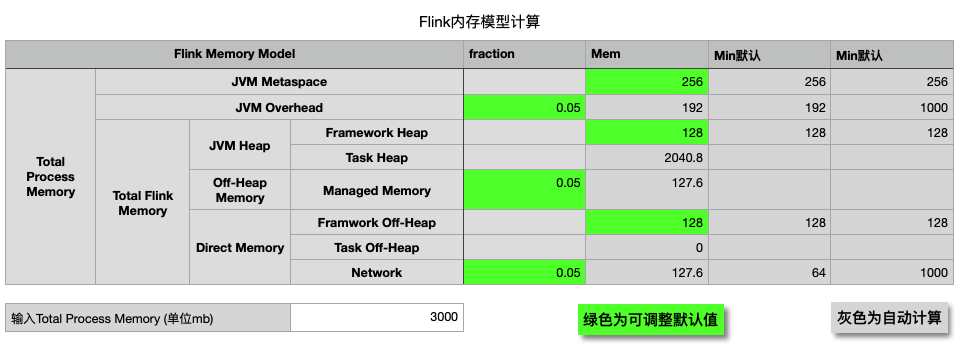
内存模型计算 - 一些带有默认值的