
数据湖概念性调研
近期数仓建设统一实时数据系统和离线报表无从着手,亟需进行架构上的升级。以下是针对传统数仓的痛点而产生的数据湖概念性调研,也包括一些大数据基本概念的阐述。
数据仓库
-
数据库(Database)
传统的关系型数据库的主要应用是联机事务处理OLTP(On-Line Transaction Processing),主要是基本的、日常的事务处理,例如业务报表。 常见的Mysql,Oracle,MariaDB等。 -
数据仓库(Datawarehouse)
数据仓库系统的主要应用主要是OLAP(On-Line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。 常见的Hive,Druid等。
E.F.Codd提出了关于OLAP的12条准则:
- OLAP模型必须提供多维概念视图
- 透明性准则
- 存取能力准则
- 稳定的报表能力
- 客户/服务器体系结构
- 维的等同性准则
- 动态的稀疏矩阵处理准则
- 多用户支持能力准则
- 非受限的跨维操作
- 直观的数据操纵
- 灵活的报表生成
- 不受限的维与聚集层次
数据分层
数据分层的目的
- 清晰数据结构
每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。 - 数据血缘追踪
简单来讲可以这样理解,我们最终给业务呈现的是一张能直接使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。 - 减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。 - 把复杂问题简单化
把一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。 - 屏蔽原始数据的异常
屏蔽业务的影响,不必改一次业务就需要重新接入数据。
收益
-
清晰数据结构
每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解 -
减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算 -
统一数据口径
通过数据分层,提供统一的数据出口,统一对外输出的数据口径 -
复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题
分层设计
[ODS] -> [DW] -> [APP]
- 数据运营层( ODS )
存放接入的原始数据。 - 数据仓库层(DW)
存放要重点设计的数据仓库中间层数据。 - 数据应用层(APP)
面向业务定制的应用数据
数据运营层ODS
是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的 ETL 之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。
一般来讲,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD层来做。
数据仓库层DW
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从 ODS 层中获得的数据按照主题建立各种数据模型。 DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Service)层。
- 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。
另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。
- 数据中间层:DWM(Data WareHouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。
直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。
- 数据服务层:DWS(Data WareHouse Service)
又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
一般来讲,该层的数据表会相对比较少,一张表会涵盖比较多的业务内容,由于其字段较多,因此一般也会称该层的表为宽表。
在实际计算中,如果直接从DWD或者ODS计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM层先计算出多个小的中间表,然后再拼接成一张DWS的宽表。由于宽和窄的界限不易界定,也可以去掉DWM这一层,只留DWS层,将所有的数据在放在DWS亦可。
数据应用层
主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、PostgreSql、Redis等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。比如我们经常说的业务数据,一般就放在这里。
传统数仓痛点
传统数仓一般落地在HDFS中,这会导致一些问题
- 处理成本大
批量导入到文件系统的数据一般都缺乏全局的严格schema规范,下游的Spark作业做分析时碰到格式混乱的数据会很麻烦,每一个分析作业都要过滤处理错乱缺失的数据,成本较大。 - 读取不友好
数据写入文件系统这个过程没有ACID保证,用户可能读到导入中间状态的数据。所以上层的批处理作业为了躲开这个坑,只能调度避开数据导入时间段,可以想象这对业务方是多么不友好;同时也无法保证多次导入的快照版本,例如业务方想读最近5次导入的数据版本,其实是做不到的。 - 无法高效更新/删除历史数据
parquet文件一旦写入HDFS文件,要想改数据,就只能全量重新写一份的数据,成本很高。事实上,这种需求是广泛存在的,例如由于程序问题,导致错误地写入一些数据到文件系统,现在业务方想要把这些数据纠正过来;线上的MySQL binlog不断地导入update/delete增量更新到下游数据湖中;某些数据审查规范要求做强制数据删除,例如欧洲出台的GDPR隐私保护等等。 - 文件系统负载大
频繁地数据导入会在文件系统上产生大量的小文件,导致文件系统不堪重负,尤其是HDFS这种对文件数有限制的文件系统。 - 回溯成本高
多份全量存储带来的存储浪费,数仓设计中为了保证用户可以访问数据某个时间段的历史状态,会将全量数据按照更新日期留存多份,故大量未变化的历史冷数据会被重复存储多份,带来存储浪费。 - 调度启动晚
大规模的数据落地HDFS后,只能在凌晨分区归档后才能查询并做下一步处理; 数据量较大的RDS数据同步,需要在凌晨分区归档后才能处理,并且需要做排序、去重以及 join 前一天分区的数据,才能产生出当天的数据。 - 更新模式重
存在较多数据的冗余更新增量数据的分布存在长尾形态,故每日数仓更新需要加载全量历史数据来做增量数据的整合更新,整个更新过程存在大量历史数据的冗余读取与重写,带来的过多的成本浪费,同时影响了更新效率。 - 重复读取多
仅能通过分区粒度读取数据,在分流等场景下会出现大量的冗余 IO。
数据湖
概念
数据湖(Data Lake)是可以存储大量结构化、半结构化和非结构化数据的存储仓库。它是一个以其原生格式存储每种类型数据的场所,对帐户大小或文件没有固定限制。它提供大量数据,以提高分析性能和原生集成。
数据湖就像一个大容器,与真实的湖泊和河流非常相似。就像在湖中有多个支流进入一样,数据湖具有结构化数据,非结构化数据,机器对机器,实时流经的日志。
数据湖使数据更易处理,是一种经济高效的方式来存储组织的所有数据以供以后处理。数据分析师可以专注于发现数据中的有意义的模式,而不是数据本身。
与将数据存储在文件和文件夹中的分层数据仓库不同,Data lake具有扁平的体系结构。数据湖中的每个数据元素都有一个唯一的标识符,并用一组元数据信息进行标记。
数据湖VS数据仓库
| 参数 | 数据湖 | 数据仓库 |
|---|---|---|
| 数据 | 存储任何内容 | 仅关注业务流程 |
| 处理 | 大部分未经处理 | 高度处理 |
| 数据类型 | 非结构化,半结构化,结构化 | 表格形式和结构 |
| 任务 | 共享数据管理 | 针对数据检索进行了优化 |
| 敏捷 | 高度敏捷,根据需要配置和重新配置 | 较之不敏捷,配置固定 |
| 用户 | 数据科学家 | 业务专业人员 |
| 存储 | 低成本存储 | 快速响应的昂贵存储 |
| EDW更换 | 可以作为EDW来源 | 与EDW互补(不可替代) |
| 模式 | 读时模式(无预定义) | 写时模式(预定义) |
| 数据处理 | 帮助快速提取新数据 | 耗时 |
| 数据粒度 | 粗 | 细 |
| 工具 | Hadoop/ Map Reduce | 主要商业工具 |
架构
示例架构
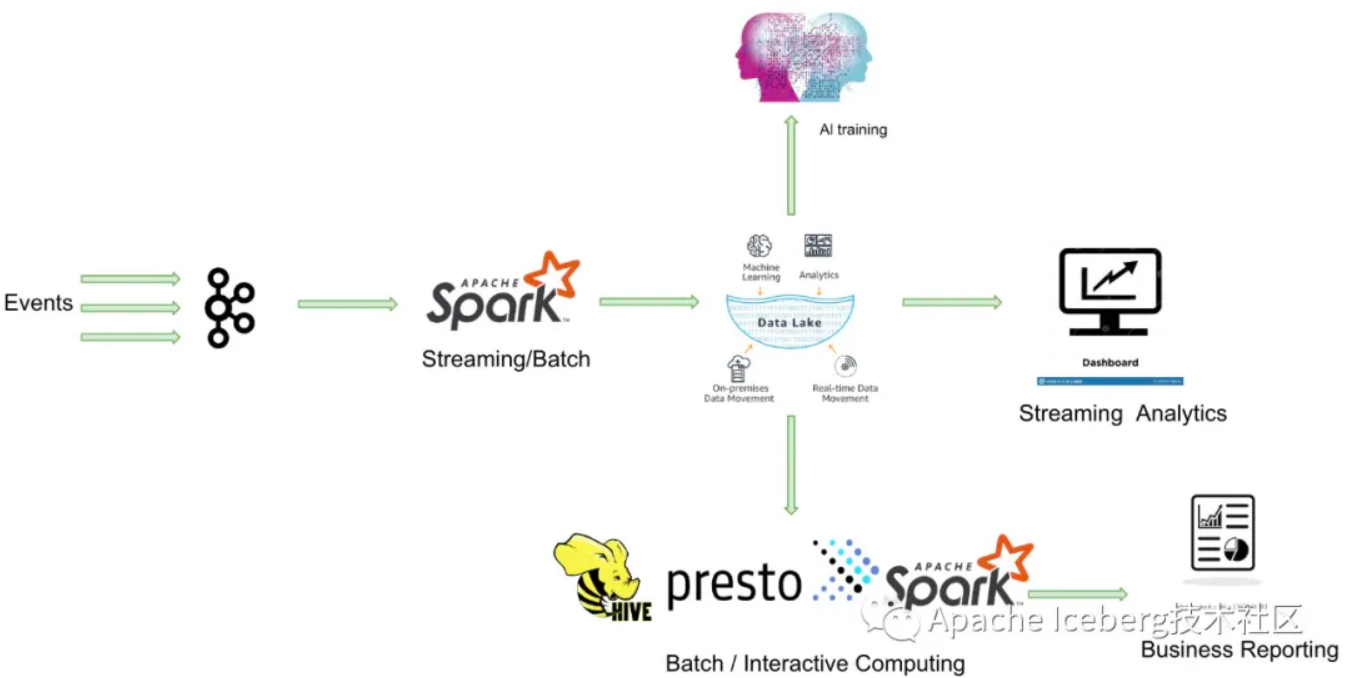
方案选型
存储引擎开源方案主要包括Hudi,Iceberg,Delta三大产品。
| Hudi | Iceberg | Delta | |
|---|---|---|---|
| 引擎支持 | Spark、Flink | Spark、Flink | Spark |
| 原子语义 | Delete/Update/Merge | Insert/Merge | Delete/Update/Merge |
| 流式写入 | 支持 | 支持 | 支持 |
| 文件格式 | Avro、Parquet、ORC | Avro、Parquet、ORC | Parquet |
| MOR能力 | 支持 | 不支持 | 不支持 |
| Schema Evolution | 支持 | 支持 | 支持 |
| Cleanup能力 | 自动 | 手动 | 手动 |
| Compaction | 自动/手动 | 手动 | 手动 |
| 小文件管理 | 自动 | 手动 | 手动 |
Delta的房子底座相对结实,功能楼层也建得相对比较高,但这个房子其实可以说是databricks的,本质上是为了更好地壮大Spark生态, 在delta上其他的计算引擎难以替换Spark的位置,尤其是写入路径层面。
Iceberg的建筑基础非常扎实,扩展到新的计算引擎或者文件系统都非常的方便, 但是现在功能楼层相对低一点,目前最缺的功能就是upsert和compaction两个,Iceberg社区正在以最高优先级推动这两个功能的实现。
Hudi的情况要相对不一样,它的建筑基础设计不如iceberg结实, 举个例子,如果要接入Flink作为Sink的话,需要把整个房子从底向上翻一遍,把接口抽象出来,同时还要考虑不影响其他功能, 当然Hudi的功能楼层还是比较完善的,提供的upsert和compaction功能直接命中广大群众的痛点。
期待架构
- 平台支持流批一体,统一实时与离线逻辑;
- 利用Flink + Hudi技术栈搭建实时数仓,构建kafka -> ods -> dwd -> olap的实时数据链条,满足业务近实时需求
- 利用hive构建数据分析系统,提供前端界面,实现低门槛数据分析
收益与风险
使用数据湖的主要好处如下:
- 充分帮助产品化和高级分析
- 提供经济高效的可扩展性和灵活性
- 从无限的数据类型中提供价值
- 降低长期持有成本
- 允许经济的存储文件
- 快速的适应变化
- 数据湖的主要优势是不同内容源的集中化
- 各个部门的用户可能遍布全球,可以灵活的访问数据
使用数据湖的风险如下:
- 一段时间后,数据湖可能会失去相关性和动力
- 数据湖的设计风险较大
- 非结构化数据可能导致无法掌控的混乱、不可用的数据、不同且复杂的工具、企业范围的写作、统一、一致和通用问题
- 增加了存储和计算的成本
- 无法从数据打交道的其他与人那里得到见解
- 数据湖最大的风险是安全和访问控制。有时,数据在没有任何监督的情况下放入湖中,某些些数据具有隐私和监管要求
参考文档
- https://www.cnblogs.com/itboys/p/10592871.html
- https://segmentfault.com/a/1190000020385389?utm_source=sf-related
- https://mp.weixin.qq.com/s?__biz=MzkwOTIxNDQ3OA==&mid=2247532544&idx=1&sn=86b24d40316f6b8d0be6c82606bcfb7f&source=41#wechat_redirect
- https://mp.weixin.qq.com/s/2WUZhMnNfY4mzEng9TZ2Uw
- https://segmentfault.com/a/1190000040715962
- https://zhuanlan.zhihu.com/p/346546088