
应用容器化改造的设计原则及模式
前言
传统应用在应对流量突发等情况时需要一个完善的紧急响应机制,比如自动弹性伸缩。但由于软硬件限制,自动弹性伸缩在物理机上实现复杂。
尽管kubernetes学习路线陡峭,复杂度高,但是考虑到成本和效率,推进应用进行容器化改造是一个收益率很高的事情。
在经历数次微博流量飙升导致深夜紧急手动扩容后,我终于下定决心将两个核心应用迁移到容器上了。
当然,并不是所有应用都适合容器化,传统应用进行容器化也需要进行一些适配性地改造。
本文是我调研容器化的改造设计原则及模式的成果。
设计原则
单一职责原则

字面意识就是只做一件事,并把它做好。
根据Docker最佳实践解释,一个容器应当仅包含一个进程。 此处的进程是指具有唯一父进程且可能拥有多个子进程的单个软件。
目的是为了增加镜像的可复用性和可移植性,单父进程带来的相同的生命周期和状态也便于kubernetes管理。
生产环境中不可避免会遇到一些例外。一些复杂的场景需要多个进程协调,此时可以使用边车模式(sidecar)解决。比如tomcat日志归集。
高可观测性原则
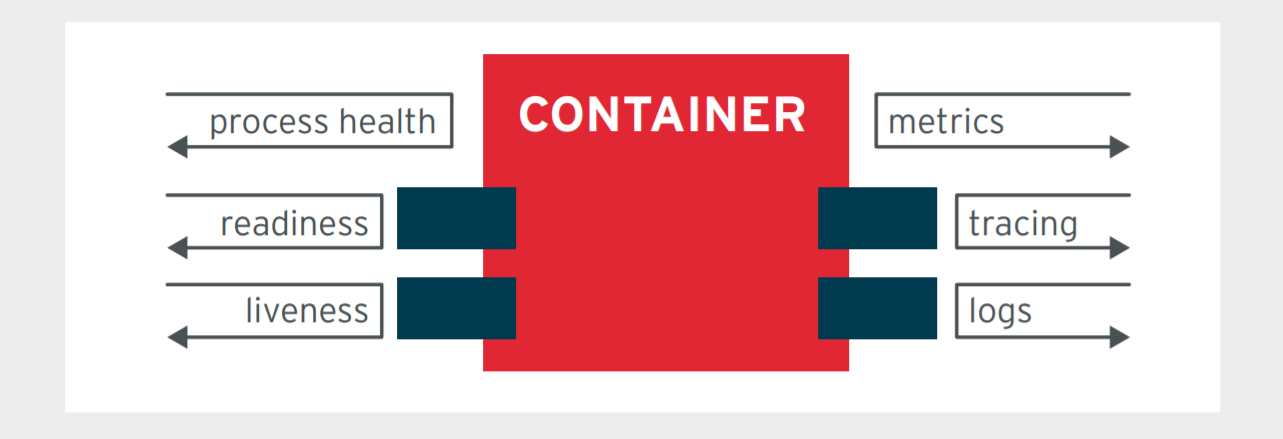
容器的设计决定了它的不便观测性,一个运行中的容器对管理者来说是一个黑盒状态,因此不能像虚拟机一样随时TTY登陆查看容器内部的状态,包括进程的日志,进程的启动等。
那么探针的设计就显得格外重要了。通过探针,kubernetes可以知晓容器的存活,服务就绪状态等。
除了探针外,我们还需要设计日志接口和监控接口来对接Fluentd,Prometheus等工具进行日常操作,比如日志归集,指标监控等。
总结下来,容器化的应用需要做好三类接口设计,以便于通过平台进行状态管理和维护:
- 探针
- 日志
- 监控
生命周期符合性原则

kubernetes这类平台为了方便管理容器的生命周期,会产生各种各样的events。这类事件主要是通过Linux信号进行传递,比如SIGTERM和SIGKILL。
因此,在设计容器应用的时候,开发者需要对这类事件做出恰当的反应逻辑规划并保持符合性。比如进程能接受SIGTERM信号后优雅退出。
镜像不变性原则
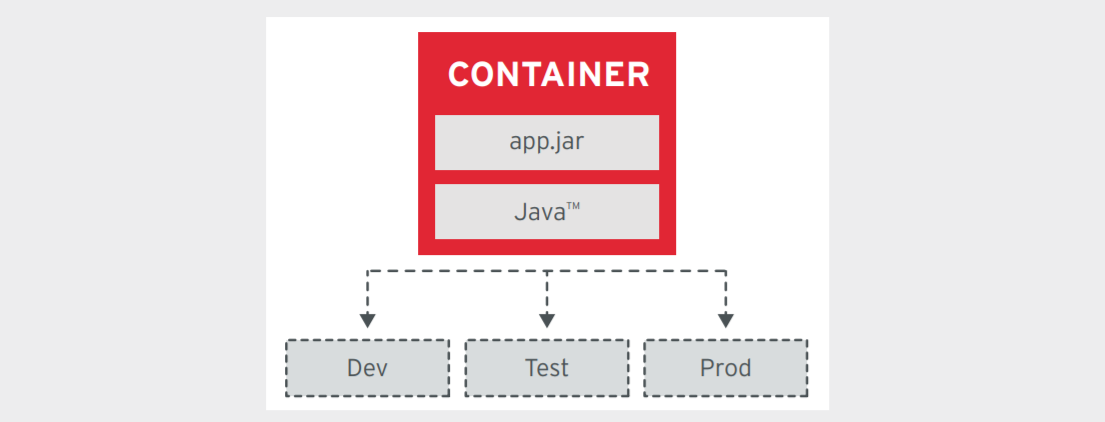
这个原则意味着什么呢?每次变更应该是重新构建一个镜像并应用于所有环境。
对于一些不同的环境需求,比如开发环境,测试环境,可以通过外部存储runtime数据来进行区分。
进程可弃型原则

无状态的应用是最适合容器化的,当然有状态的应用也可以通过外部持久卷的方式存储运行时数据来实现这一原则。
自包含原则
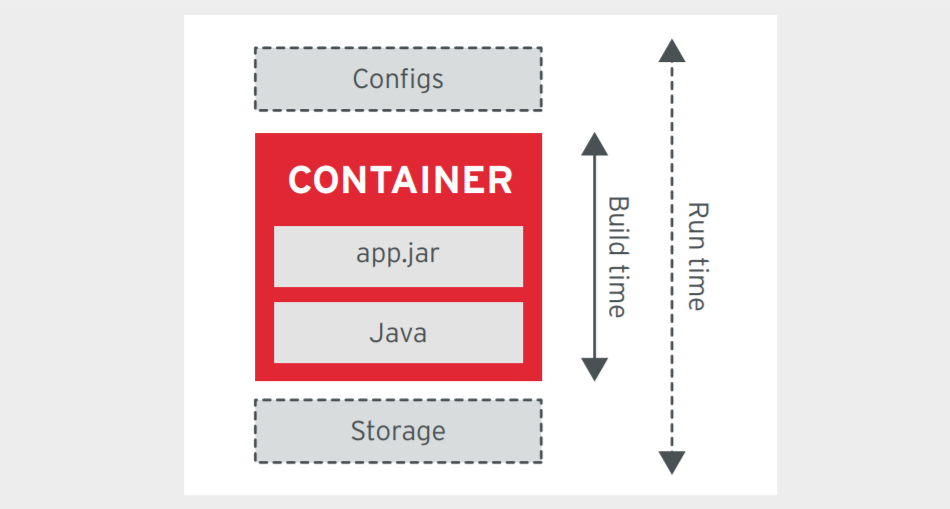
运行时限制原则
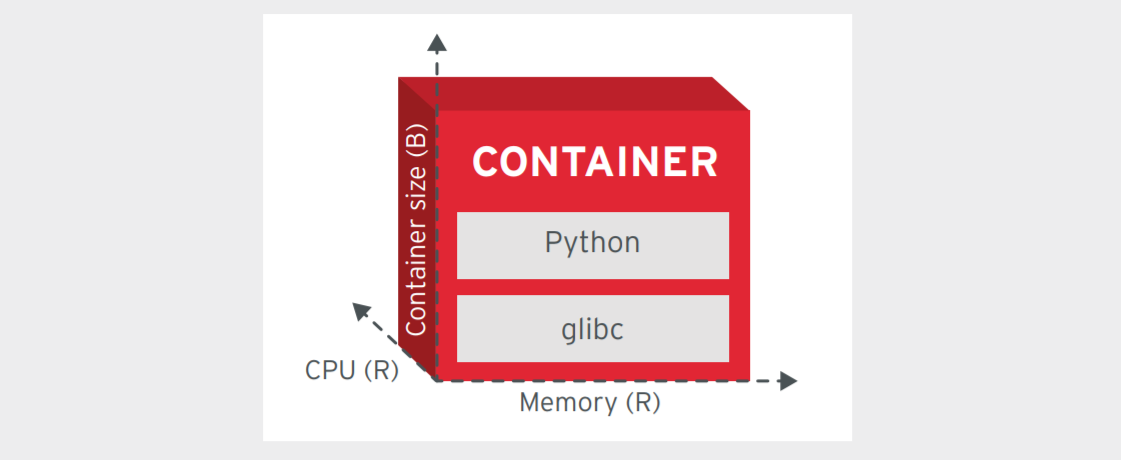
设计模式
Pod是kubernetes的基本执行单元,封装了应用程序容器、存储资源、唯一网络IP、控制选项等,由单个容器或者多个强耦合共享资源的容器组成。
这些容器集合共享一个network,特定namespace,volume,已经声明的spec规范,并存于同一个node上
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;可以通过localhost通信;
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
- UTS命名空间:Pod中的多个容器共享一个主机名;
- Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volumes;
Pod中容器是怎么设计安排的,也有一定的模式遵循。
单容器模式
单容器模式是最简单的一种,遵循上文所述的七种设计原则,开放日志接口,监控接口,生命周期管理。
单节点多容器模式
有一些普遍存在的场景中,单容器模式由于遵守单一职责原则,无法满足所有需求。此时,可以采用多容器模式,在同一个Pod中运行多个容器,通过共享Volume,命名空间,网络等实现。
Sidecar
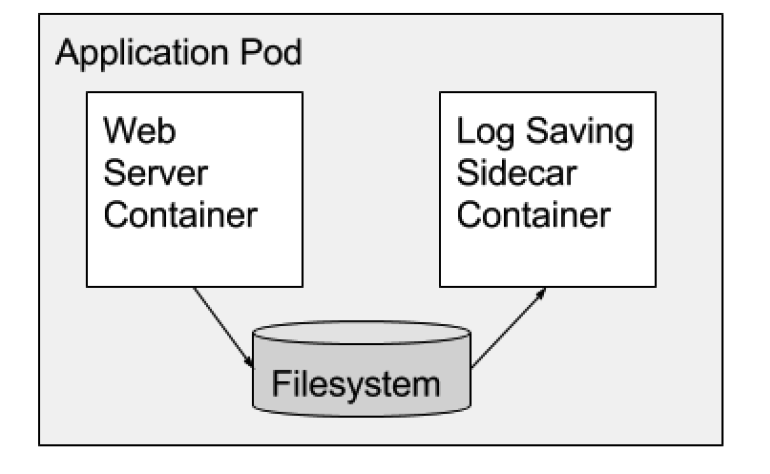
除此之外,边车模式还可以作为主程序的配置,服务代理等。
Ambassador
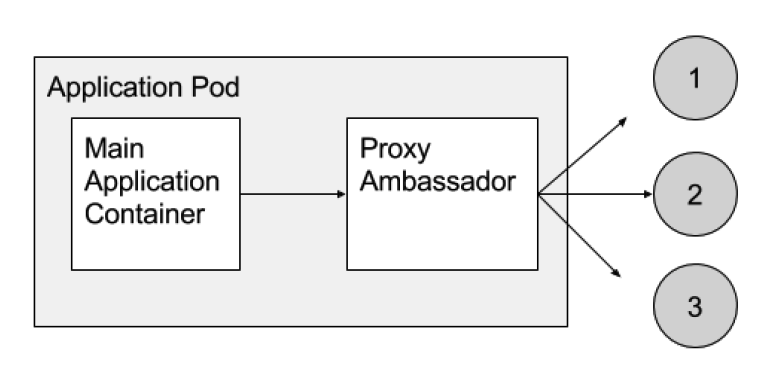
这个模式并不怎么常用。
Adapter
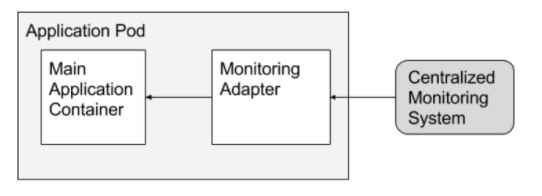
举个例子,对于监控接口来说,外界可能的方案包括zabbix,prometheus等,适配器模式的功能就是根据不同的方案输出对应格式的数据。
说到这里可能会存在一些疑惑,为什么开发者不把这些接口的规约定义在程序里?其实,适配器模式主要是为了一些开源程序或者非自研程序设计的,这样开发者就不需要更改源程序进行二次开发。
多节点模式
分布式的应用需要模块化的设计,多容器之间的彼此协调。
Leader Election
对于分布式系统来说,最为常见的问题就是选举。这类应用通常需要一个Leader,而其他副本则作为备选和选举者,当Leader节点挂掉后,需要通过其他副本选举出一个新的Leader。
通过编程实现的选举一般来说逻辑复杂,实现困难。这时候可以把选举逻辑剥离出来成为选举专属容器,由更专业的工程师负责,共同调度。应用开发者只需要关注核心逻辑即可。
Worker Queue
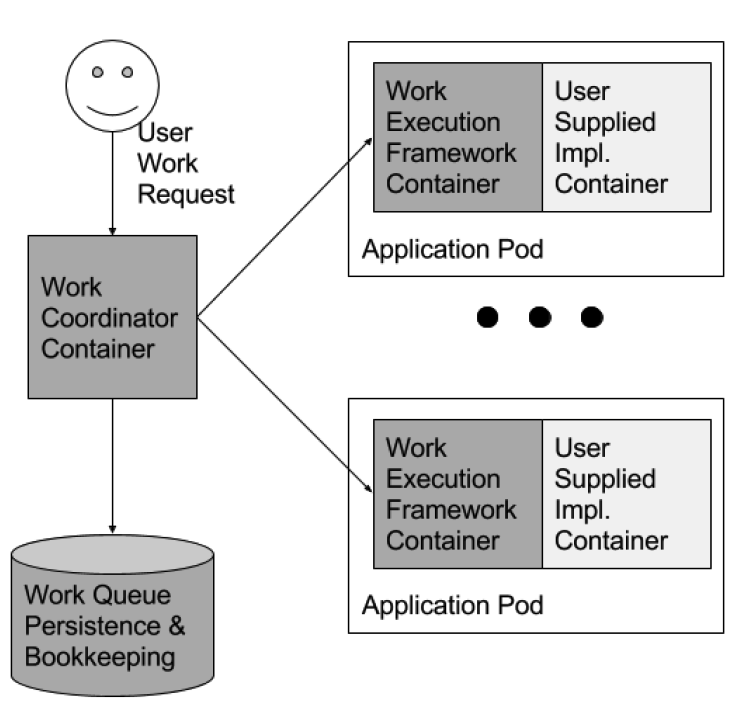
容器针对run()和 mount()接口的实现,可以把实现通用的工作队列变得更为简单直接,可以把任何的代码打包成容器,与任意数据构建成一个完整的工作队列系统。
Scatter/Gather
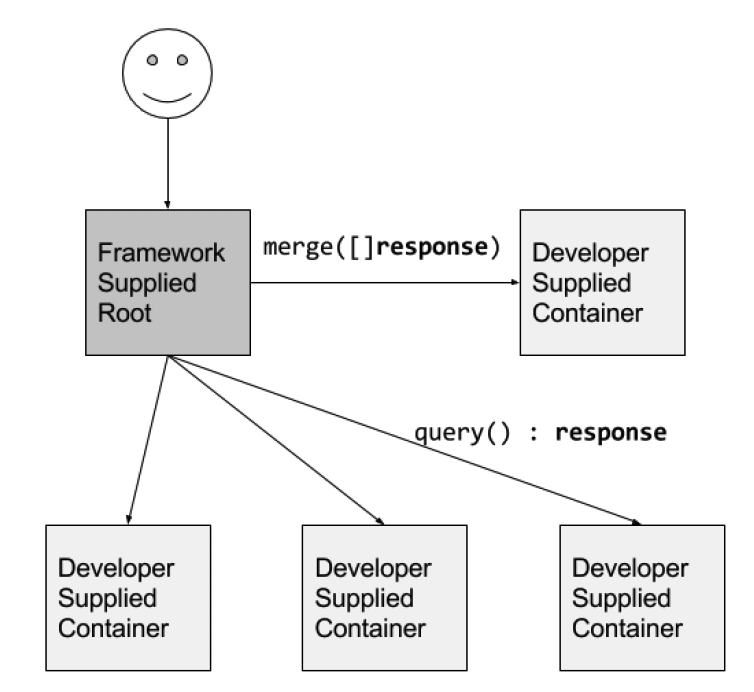
实现分散/收集系统,用户需要提供两类容器。首先,一类容器实现叶子节点计算,这个容器执行部分计算并返回相应的结果。 第二种容器是合并容器,这个容器需要汇总所有叶子容器的计算结果,并组织成一个单一的响应后输出。
容器化改造方法
以下是我针对容器化列出的一些改造点,仅供参考。
- 探针开发
主要包括健康探针和就绪探针。健康探针用于心跳存活监控,就绪探针用于deployment获取Pod健康状况,ready后再分发流量请求。 - 目录改造
主要是去掉了强目录依赖,更新为相对目录。这其实是之前项目的陋习,一直依靠标准化部署手册来维护。还有就是趁机精简了下目录结构。 - 配置分离
主要的配置文件通过configmap实现,从主代码库分离。 - 定时任务
一些额外的定时任务通过边车模式实现。k8s原生的cronjob无法实现deamonset类的机制,只能实现单节点。可以自定义死循环程序实现。 - 监控及日志收集
原fluent-bit和prometheus的各类exporter都已经全部deamonset化,其配置文件也均由configmap托管。 - 灰度发布
通过建立多个deployment,匹配不同的标签实现。 - 启停方式
容器化后没有reload概念了。每次配置更新都是重建的过程,因此,去除了没意义的生命周期管理脚本。 - 功能拆分
原应用依赖定期更新的IP库,本次容器化将IP库解析拆分成微服务,很大程度上精简了镜像大小。
参考文档
- https://www.redhat.com/en/resources/cloud-native-container-design-whitepaper
- https://my.oschina.net/taogang/blog/1809904
- https://kubernetes.io/blog/2018/03/principles-of-container-app-design/
- https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/
- https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45406.pdf